ZALEŻNOŚCI POMIĘDZY USŁUGAMI
W świecie mikroserwisów jednym z zagadnień jest wzajemna zależność pomiędzy wieloma usługami. Usługi bardziej złożone nie są atomowe lecz składają się z grafu wzajemnych wywołań.
Wykorzystanie narzędzi i mechanizmów do monitorowania, diagnozowania i analizy takich zależności oraz wzajemnego wpływu usług na efektywność działania jest ważnym aspektem środowiska mikroserwisowego.
CZYM JEST JAEGER
Jaeger jest narzędziem open source do tzw. distributed-tracing czyli śledzenia wzajemnej zależności wywołań między rozproszonymi serwisami. Pozwala na monitorowanie i badanie problemów i zagadnień z tym związanych w środowisku mikroserwisów takich jak m.in:
- propagacja kontekstu pomiędzy grafem wywołań usług
- monitorowanie rozproszonych transakcji
- lokalizowanie źródła błędu w sekwencji wywołań
- analiza zależności pomiędzy usługami
- analiza wydajności usług
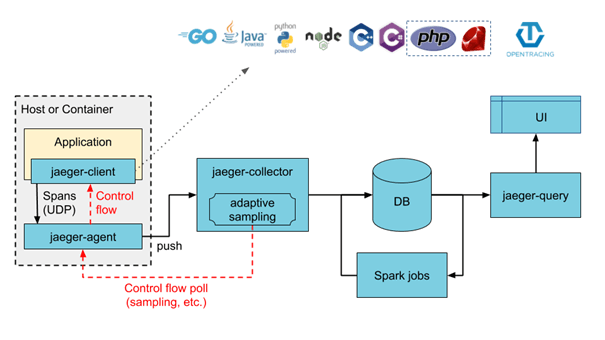
JAK DZIAŁA JAEGER
Aby móc przekazywać informacje o przetwarzaniu do Jaegera śledzony mikroserwis musi zostać zainstrumentowany kodem jaeger-client, który umożliwi przekazywanie danych raportowych do jaeger-agenta działającego na tym samym hoście na którym uruchamiany jest mikroserwis.
Jaeger wspiera instrumentację kodu w Go, Javie, NodeJS, Pythonie, C++ i C#.
Następnie jaeger-agent przesyła poprzez mechanizm strumieniowy (może być to inny host) dane do modułu jaeger-colector. Collector odbiera dane o trace wywołań, waliduje je oraz odpowiednio przetwarza i indeksuje tak aby dane o szczegółach i zależności wywołań mogły być wyszukiwane przez moduł jaeger-querry. Dane te mogą być zapisane w sposób persystetny lub być przechowywane w pamięci. Do przesyłania informacji z agentów do kontrolera Jaeger wykorzystuje Kafkę, natomiast do analizy wyszukiwania danych o „trace” wykorzystywany jest elasticsearch. Dane mogą być także zapisywane przez Jaeger do bazy Cassandra.
Użytkownikowi do analizy wizualnej udostępniana jest konsola Jaeger prezentująca w formie graficznej wszystkie informacje o zależnościach i szczegółach przetwarzań. Udostępnia ona m.in. wyszukiwarkę za pomocą której możemy wyszukiwać bazę z „trace” podając nazwy usług, tagi parametry ograniczenia czasowe.
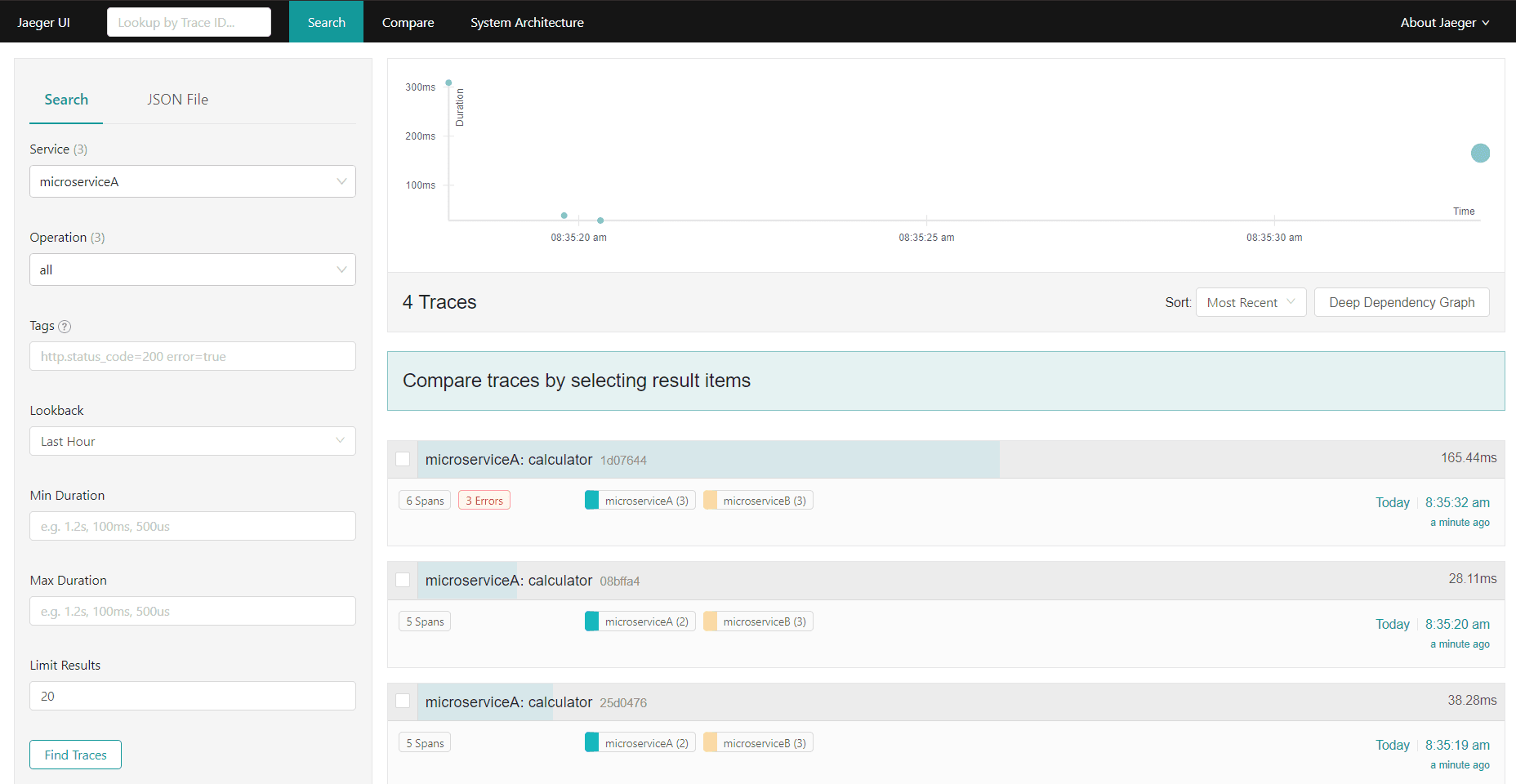
Po znalezieniu interesującego nas przebiegu „trace” możemy wyświetlić jego szczegóły grafu wywołań usług wraz z wzajemnymi, zależnościami i szczegółami w tym m.in. czasu przetwarzania.
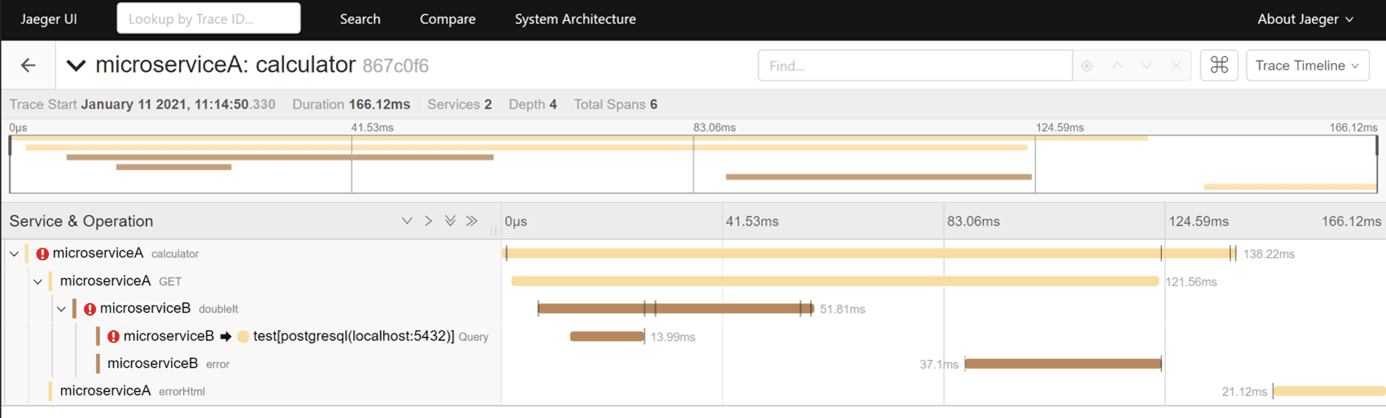
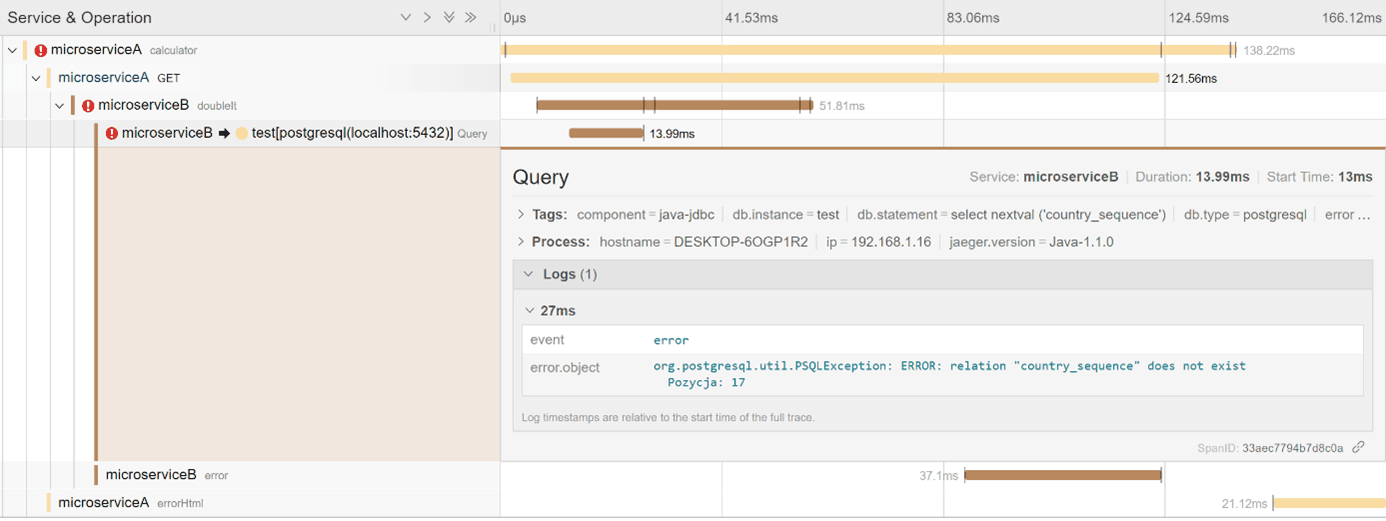
Na konsoli widoczne są także błędy i wyjątki.
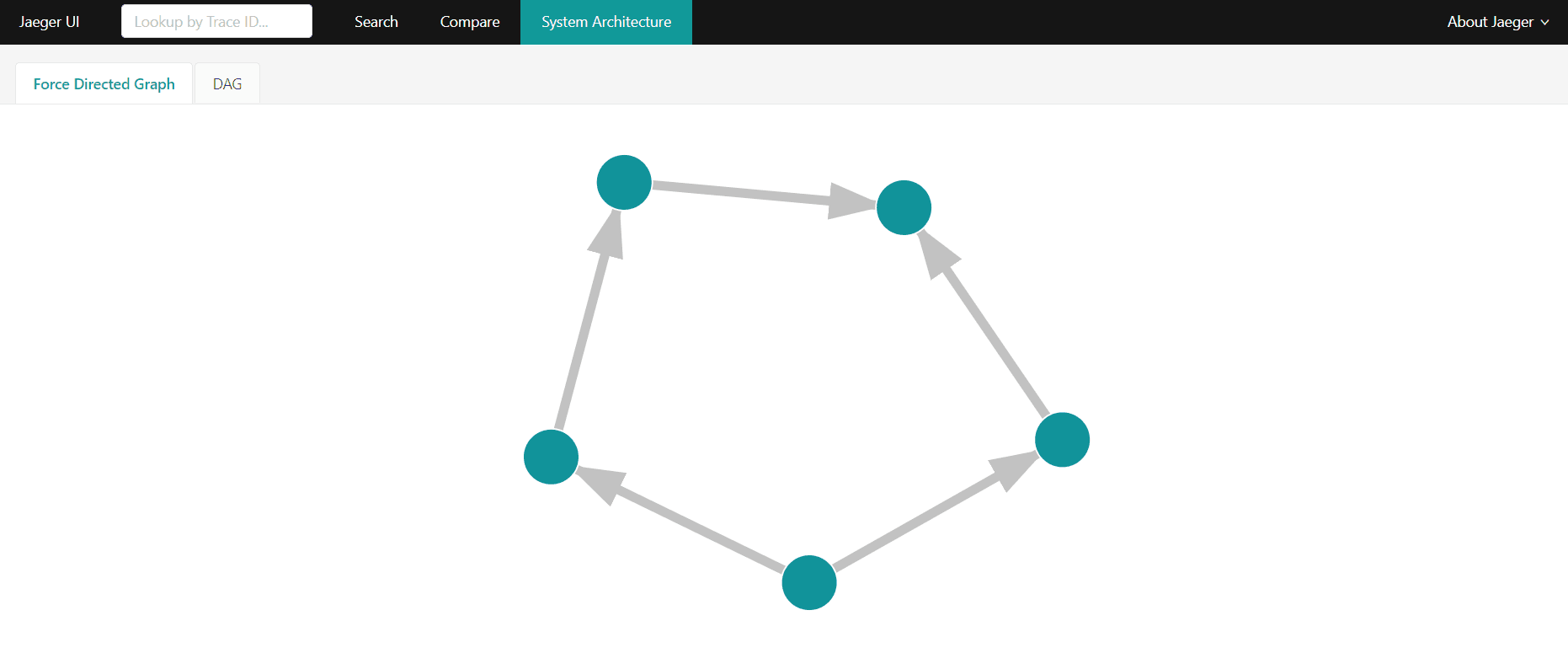
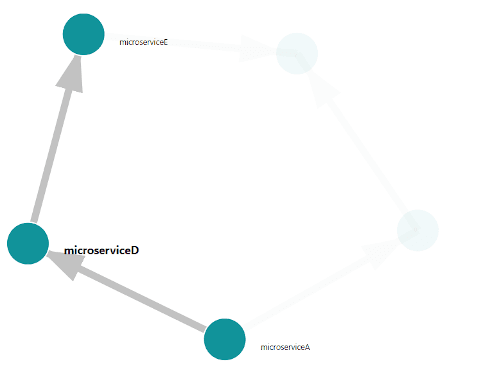
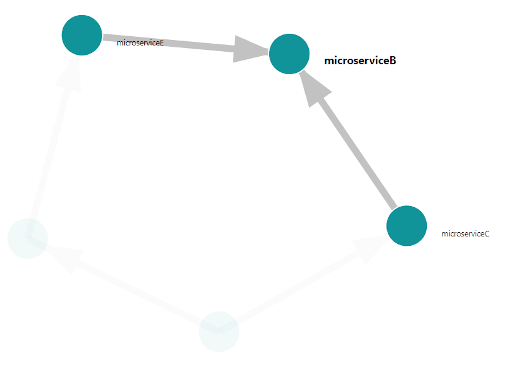
Konsola udostępnia także mechanizm wizualizacji architektury systemu identyfikowanej na podstawie grafów wywołań (zakładka System Architecture). Prezentowane jest to w postaci grafu skierowanego gdzie węzłami są usługi a łukami kierunki zależności (który mikroserwis korzysta z jakich usług).
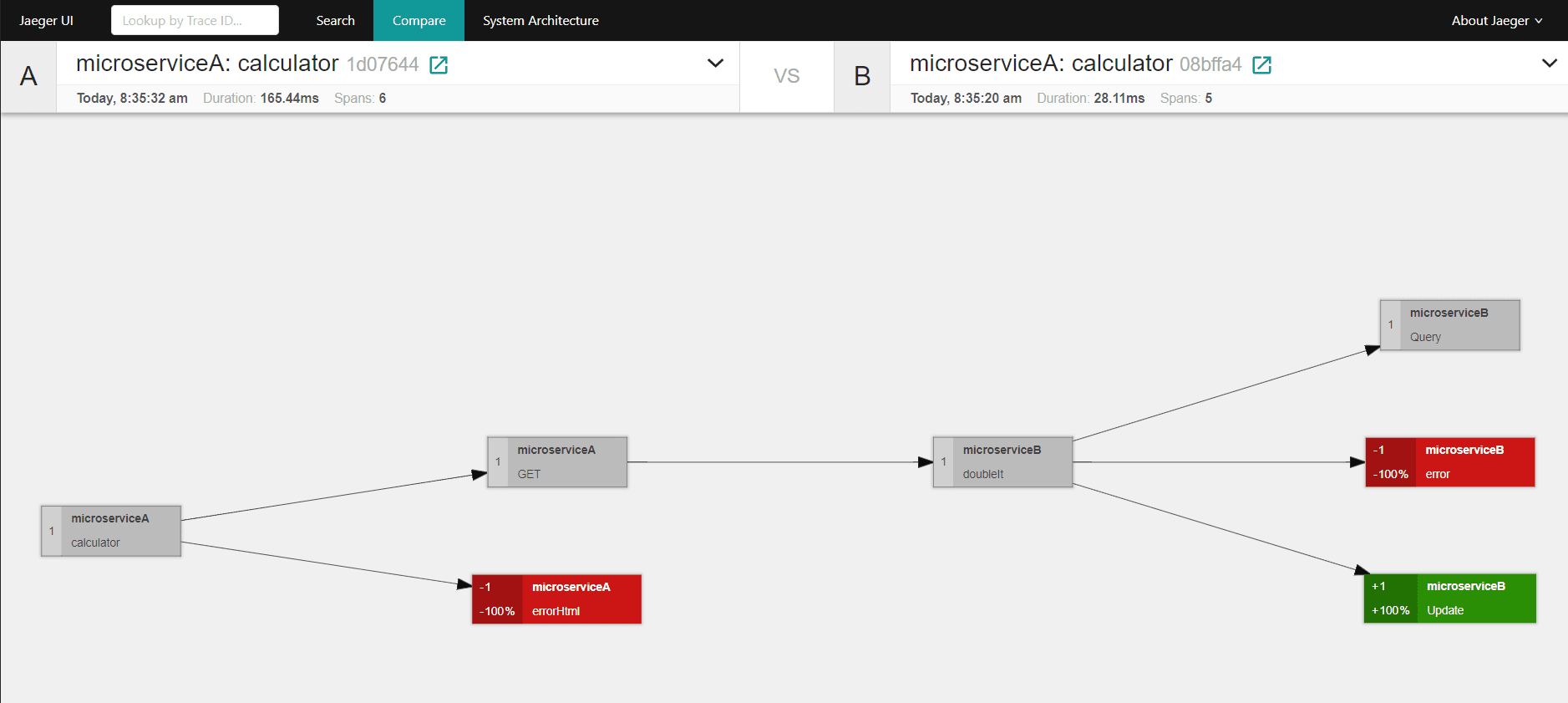
W konsoli mamy dostępne także narzędzie do porównywania dwóch wywołań. Otrzymany diagram prezentuje nam jakie elementy wywołania się pokrywają (szary kolor), jakie zostały usunięte względem wzorcowego przetwarzania (czerwone), oraz które zostały dodane (zielone).
Najszybszym sposobem wykorzystania Jaeger jest wykorzystanie dostępnego skonfigurowanego obrazu docker umożliwiającego uruchomienie wszystkich modułów Jaegera w ramach pojedynczego kontenera. Wszystkie moduły są wtedy uruchamiane w ramach jednego hosta.
Taką konfiguracja daje nam możliwość przetestowania Jaegera lub wykorzystania go do szybkiej konfiguracji środowiska do incydentalnej analizy.
JAEGER NA KLASTRZE KUBERNETES
Jaeger posiada przygotowaną konfigurację obiektów do wdrożenia na klastrze Kubernetes w oparciu o wzorzec Kubernetes Operator. Wdrożenie go na klastrze umożliwia generyczną instrumentację mikroserwisów.
Po zainstalowaniu Agenta na klastrze będzie on wyszukiwał, monitorował i instrumentował pody posiadające annotację sidecar.jaegertracing.io/inject w Deploymencie informującą, że wskazany pod powinien być przez Agenta zainstrumentowany kontenerem typu sidecar z jaeger-agent do przesyłania informacji trace.
To które z przestrzeni typu namspace jaeger-agent będzie monitorować decydujemy parametryzując obiekt K8S RoleBinding nadający uprawnienia kontu Service-Account na którym operuje jaeger-opearator. Domyślnie jest to tylko przestrzeń, w którym Agent zostanie wdrożony.
Ostatnim krokiem jest deployment komponentów Jaegera na klastrze poprzez wykorzystanie obiektu CRD ( Custom Resource Definition) Jaeger. Domyślną konfiguracja jest tzw. strategia "allInOne" – czyli uruchomienie agenta, collectora, ingestera i konsoli na jednym pod. Należy wspomnieć, że na klastrach produkcyjnych konfiguracja deploymentu tych komponentów jest nieco bardziej złożona. W takich przypadkach należy wykorzystywać strategie "production" lub "streaming" umożlwiające bardziej złożone konfiguracje wdrożeniowe niezbędne na środowiskach produkcyjnych dające m.in.:
- możliwość wyboru i definiowania parametrów konfiguracji usługi do zapisu persystentego (Kafka, Elasticsearch, Casandra)
- możliwość korzystania z zewnętrznych klastrów Kafka lub Elasticearcha
- możliwość zarządzania autoskalowalnoscią i replikowalnością collectora
PODSUMOWANIE
Jaeger jest wartościowym narzędziem typu open-soruce do wsparcia w obszarze analizy i monitorowania mikroserwisów na klastrze Kubernetes, które okazuje się być bardzo przydatne zarówno dla zespołów utrzymujących klaster do identyfikacji źródła błędu jak i zespołów developerskich do identyfikacji „wąskich gardeł” i optymalizacji wydajności kluczowych usług.